
Chronomics® AI driven & DNA methylation based personalized medicine
Chronomics collects more than 380 raw variables that comprehensively cover all lifestyle and environmental risk factors. These raw variables can be further combined to obtain additional insights, such as those coming from clinically-validated scoring systems. Its also retrieve disease history for major disease classes from the latest version in the WHO International Classification of Diseases (ICD-11).
The quantified metadata can be leveraged for the following purposes:
- Define new biomarkers (epigenetic indicators) using the epigenetic modelling framework previously outlined and the automation capabilities we have built (see next section),
- Explore the vast space of associations between metadata variables and between metadata and epigenetic indicators. This can validate current biomarkers and help to create personalized improvement recommendations.
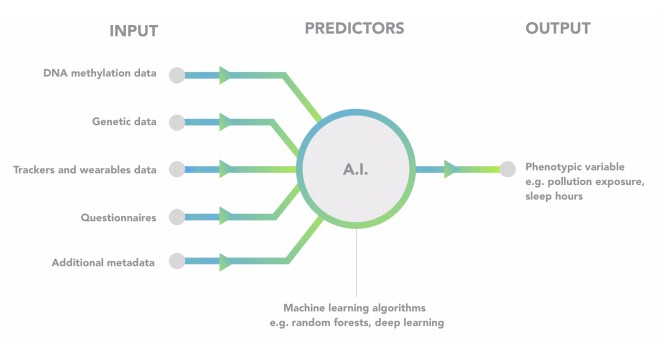
In order to do this, they apply different AI machine learning algorithms (e.g. random forests, elastic net, CNNs, etc.) that use as input mainly the epigenetic data obtained from their pipeline. Additionally, other sources of input data, such as genetic data, wearable information or questionnaires, can be used depending on the model of interest. Once the model is trained on a population of subjects, it can be used to infer the phenotypic variables of a new customer using the information derived from the patient sample.
Chronomics sequences the library and generates the raw sequencing data using the latest in next-generation sequencing technology. This data is then uploaded to its cloud-computing ecosystem (built on top of Amazon Web Services) using a secure connection. Once the data is there, it gets processed with automated bioinformatics pipelines, that extract the epigenetic information together with some genetic information from the customer and a lot of additional metadata, which is stored in their databases. The epigenetic information is used as input for its proprietary AI algorithms, that generates as output the predictions about different phenotypes. This information is then provided in an easy-to-understand and customisable way to the user through the digital platform. An unique barcode allows then to track the sample along this complicated journey whilst ensuring at the same time that the identity of the customer remains secret to all the people involved in the processing.